Hermes Agentに「長期記憶」を与えるGBrainの仕組みと活用法
この記事は約 20 分で読めます
AI エージェントに「先週の打ち合わせで決まったこと、覚えてる?」と聞いて、「すみません、記録がありません」と返されたことはありませんか。私はあります。何度もあります。セッションが切れたら記憶もリセット。長く付き合おうとすればするほど、この壁がしんどくなる。
で、最近「それを本気で解決しようとしてるプロジェクトがある」と知って、GBrain の GitHub を開いたのが始まりです。読み始めたら止まらなくなってしまったので、Hermes Agent の公式ドキュメントと合わせて、「AI エージェントの記憶って、どう設計すればいいんだろう」という視点で整理してみます。
GBrain と Hermes Agent、この組み合わせが出てきた背景
最初に「誰が何を作ったのか」だけ整理させてください。
GBrain は、Y Combinator CEO の Garry Tan が 2026 年 4 月に公開した AI エージェント向けの記憶インフラです。MIT ライセンス、TypeScript(Bun ランタイム)、GitHub で 19,000 スター超。ここまでは「また新しい OSS か」くらいの感想だったんですが、README を読み進めて手が止まりました。これ、Tan が自分で使っている AI エージェント「OpenClaw」の本番環境でそのまま動いていて、14 万 6,000 ページ超の記憶を管理している。個人の趣味プロジェクトじゃなくて、ガチの運用基盤です。
もう一方の Hermes Agent は、AI 研究企業 Nous Research が開発するエージェントフレームワーク。GitHub 170,000 スター、300 以上の AI モデルに対応、18 以上のプラットフォームで動く。このエージェントの特徴は「学習ループが内蔵されている」こと。経験からスキルを自動生成して、7 日サイクルで評価・統合・刈り込みまでやります。
ただ、この記事で書きたいのは「すごいツールが出ました」じゃないです。AI エージェントの記憶を、どう設計・整理・検索するか。その考え方を、GBrain × Hermes Agent という実装から読み取ってみたい。そういう記事です。
GBrain の記憶操作は、ドキュメントを読んでいくと 4 つに分かれます。
- capture:情報を取り込む。CLI(
gbrain capture "内容")で手動投入もできるし、Gmail・カレンダー・議事録ツール Circleback からの自動連携もある。取り込まれた情報はinbox/に markdown で着地して、人物・企業・イベントのエンティティを正規表現で自動抽出する。ここ、LLM を一切呼ばないゼロトークンコスト設計なのが地味にいい - search:記憶を検索する。pgvector の HNSW ベクトル検索と PostgreSQL の BM25 キーワード検索を Reciprocal Rank Fusion(RRF)で融合して、バックリンクブースト・鮮度ブースト・グラフ信号を加え、最後に rerank をかける。検索精度への執着がすごい
- think:検索結果から拡張推論する。時系列データを注入して、引用付き・ギャップ分析付きで回答を返す。「ここはまだ情報が足りない」まで教えてくれるのは助かる
- dream cycle:夜間に記憶を自動整理する。extract(事実抽出)→ consolidate(古い事実に有効期限を付与)→ synthesize(compiled truth の再構築)→ publish(Git コミット)の 4 フェーズ。ここが一番「えっ」となったポイントなので、後で詳しく書きます
保存形式は markdown + YAML frontmatter。Git リポジトリが正本で、人間が直接読み書きできる。NotionでもObsidianでもなく、素のmarkdownファイルとGitという組み合わせに振り切っているのが、個人的にはかなり好みです。
補足
GBrain のベンチマーク(BrainBench、240 ページの評価コーパス)では、P@5: 49.1%、R@5: 97.9%。ベクトル検索単体より P@5 が +31.4 ポイント改善。ナレッジグラフ層を有効にすると F1 が 57.8% → 86.6%。「ハイブリッドにした意味あるの?」という疑問に、数字で答えが出ている点は説得力があります。
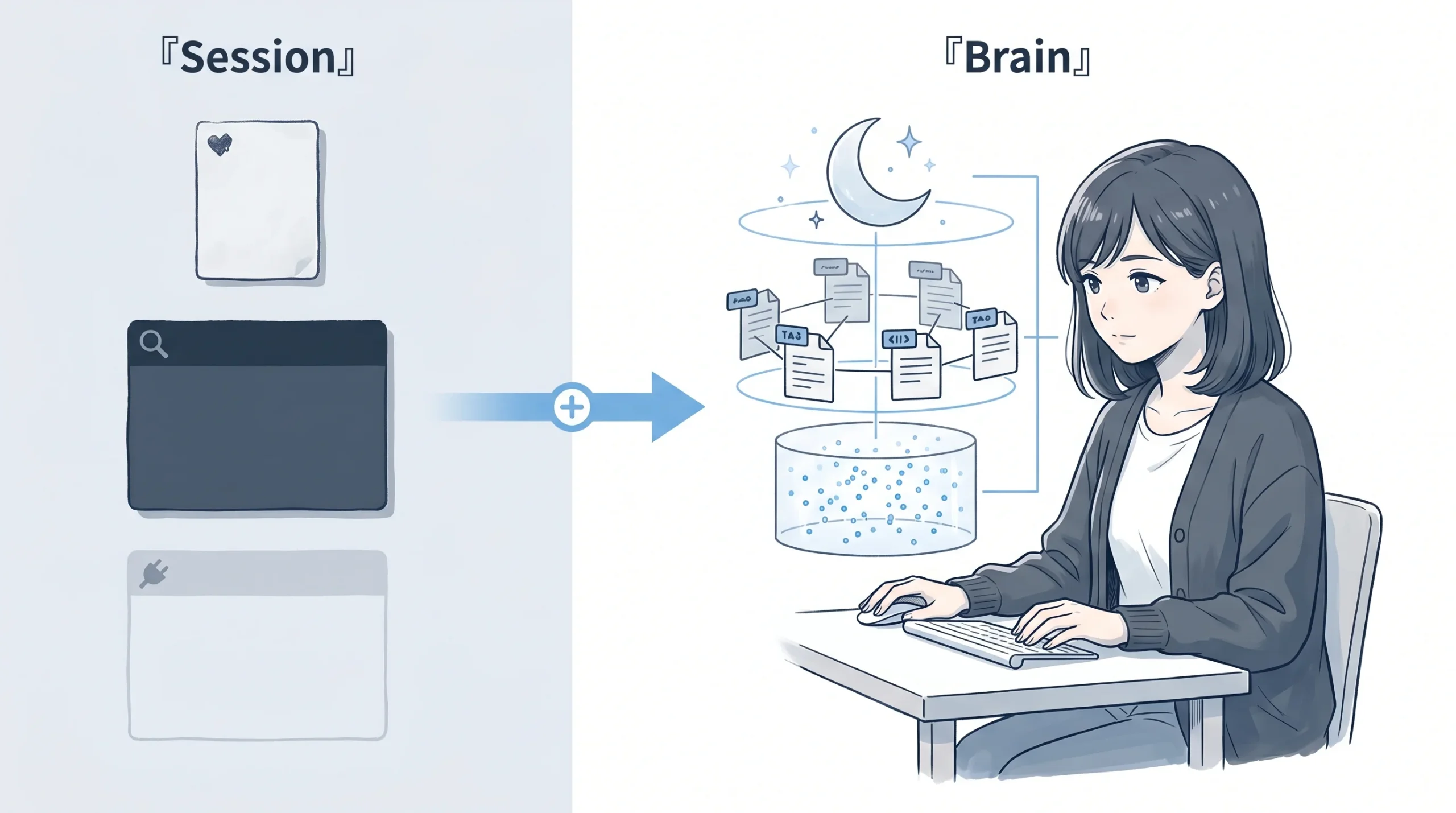
セッション記憶から「育てる記憶」へ — ここが構造的に変わる
Hermes Agent 側のメモリ構造を見てみると、3 層になっています。
- Core Memory(常時注入):
MEMORY.mdとUSER.mdの 2 ファイル。セッション開始時にシステムプロンプトへ丸ごと注入される約 1,300 トークンの永続メモリ。変更は即ディスク保存されるけど、モデルのコンテキストに反映されるのは次セッションから(Frozen Snapshot パターン) - Session Search(オンデマンド):SQLite + FTS5 で過去セッションを全文検索。15〜50ms で返ってくる
- External Provider(拡張層):Mem0、Hindsight、Holographic など 8 種類のプラグインから選んで接続。ターンごとに記憶を事前読み込みして、応答後に同期する
ドキュメントを読んで「あれっ」と思ったのが、Core Memory の容量。約 1,300 トークン。日本語で 500〜700 字くらい。付箋 2〜3 枚分です。意図的に小さくしてキュレーションを強制する設計なのはわかるけど、これを「長期記憶」と呼ぶにはちょっと無理がある。
Session Search は過去の会話をキーワードで引けるけど、やっていることは「ログの全文検索」で、記憶を育てたり、古い情報を整理したりする機能はない。
GBrain を MCP 経由で接続すると、ここに brain 層 が加わります。
ここで押さえておきたいのは
GBrain は「外部ノートアプリ」ではなく、AI が使いやすい形で記憶を整理する brain 層だということ。
Hermes Agent が「動いて考える主体」、GBrain が「記憶を整理・検索・育てるインフラ」。接続は hermes mcp add gbrain -- gbrain serve の 1 行で、74 の MCP ツールが使えるようになります。
この組み合わせで何が変わるかというと、わりと根本的に変わります。
- 前の会話を引っ張り出せる:capture で保存した内容を、セッションをまたいで search できる。「あのとき何を話したっけ」が検索で返ってくる
- 過去の判断を根拠付きで参照できる:think を使えば「前回こう判断した。根拠はこの 3 件」みたいに引用付きで返ってくる
- 記憶が自動で分類される:schema で person、company、meeting、concept など 15 タイプに自動分類。しかも
gbrain schema detectでファイルシステムから新しいタイプを提案してくれて、gbrain schema suggestで LLM が洗練させる。分類が固定じゃなくて、使いながら進化していく設計 - 夜中に勝手に整理される:dream cycle が事実を抽出して、矛盾を解消して、compiled truth を再構築して、Git にコミットしてくれる。朝起きたらナレッジが最新になっている
- 全部 markdown で読める:各ページに slug、type、tags、effective_date が YAML frontmatter で付く。CJK 対応の slug 生成も組み込み済み
あと、GBrain のページ設計で「これはよく考えてあるな」と感じたのが、上半分と下半分の分離です。上半分が「compiled truth」—— 現時点でのベストな理解。下半分が「timeline」—— いつ・どの情報源から・何がわかったかの時系列ログで、こちらは追記専用。最新の理解は書き換わるけど、証拠の原本は絶対に改変されない。この分離、自分でナレッジ管理するときにもそのまま使える考え方だと思います。
副業として狙うなら、AI 記憶設計はまだ空白地帯
これは正直に書きます。GBrain × Hermes Agent を「来月から副業にしよう」は無理です。PostgreSQL + pgvector + embedding API + MCP 設定が全部必要で、敷居が高い。
でも、だからこそ面白いんですよ。「AI エージェントの記憶をどう設計するか」を提案できる人が、今この瞬間ほぼいない。
- 記憶設計コンサルティング:「AI に長期記憶を持たせたい」と考える企業やチームに対して、GBrain の構築から schema 設計、dream cycle の頻度設定まで提案できるだけで差別化になります。何を capture して、どの schema で分類して、どのくらいの粒度で dream cycle を回すか。これを設計できること自体がスキル
- セットアップ代行:PostgreSQL + pgvector 環境の構築、Supabase 移行(
gbrain migrate --to supabase)、embedding モデルの選定。「動くところまで持っていく」だけでスポット案件として成り立つ - 議事録をナレッジに変える:Circleback の議事録を GBrain に流し込んで、dream cycle で整理して、いつでも search で引ける状態にする。「あの会議で何を決めたっけ問題」を解消するサービスとして切り出せます
注意
「AI の記憶設計ができます」と名乗っても、今すぐ案件が舞い込むわけではありません。まず自分の環境で 1 か月 GBrain を回してみて、schema の設計判断や dream cycle のクセを体感しておくのが先。経験なしに提案するのは厳しいです。
個人開発で手を動かすなら、schema カスタマイズが狙い目
GBrain の schema は「パック」という単位で管理されます。デフォルトの gbrain-base-v2 には 15 タイプ入っているんですが、gbrain schema fork gbrain-base mine で独自パックを作って、自分の用途に合わせたタイプを足していける。
ここを読んだとき、「あ、これは個人開発者が遊べるやつだ」と思いました。
- 業界特化の schema パック:医療記録用、法律判例用、不動産案件用、研究論文管理用。特定の知識構造に合った schema を設計して公開する。
gbrain schema add-type researcher --primitive entity --prefix people/researchers/ --extractable --expertみたいに CLI 1 行でタイプを追加できるので、試行錯誤のスピードが速い - 記憶付き AI アシスタント:Hermes Agent + GBrain をベースに、営業支援やカスタマーサポートに特化した AI を組む。GBrain が 74 の MCP ツールを公開しているので、エージェント側から何でも呼び出せる
- 自分の学習ログの蓄積:日々の学習を capture して、schema で分類して、dream cycle で定期整理。3 か月前に調べた技術メモを think で引き出せる個人ナレッジベースとして使う。これは私が一番やりたいパターンです
GBrain には「20 ページ未満なら schema を正式化しない」「100 ページ超えたら first-class タイプとして正当化する」というルールがあります。最初から完璧に設計しなくていい、使いながら育てればいいという思想。個人開発でものを作るときの姿勢と近くて、ここは素直に好感を持ちました。
収益化を本気で考えるなら、日本語の情報不足が逆にチャンス
これ、調べていて驚いたんですが、GBrain × Hermes Agent の日本語情報がほぼゼロです。「GBrain セットアップ」で検索しても、日本語でまともに解説している記事が見つからない。英語の README と公式ドキュメントがすべて。
- 技術ブログ・チュートリアル:セットアップ手順、dream cycle の設定、schema カスタマイズを日本語で書くだけで、検索からの流入が見込めます
- 有料コンテンツ:GBrain + PostgreSQL + pgvector の構築から運用まで、手を動かしながら進められるガイド。動画にしても需要はあるはず
- 運用コンサル:dream cycle のチューニング、embedding モデルの選定、コスト最適化を月額で支援するサービス
ただし、GBrain は 2026 年 4 月に出たばかりのプロジェクトで、更新頻度が高い。仕様がどんどん変わるので、「一度書いて放置」するタイプのコンテンツには向きません。あなたがこの分野で発信を始めるなら、バージョンアップに追従し続ける覚悟は必要です。
始めるなら最初に触れておきたいスキルとコスト感
実際に GBrain × Hermes Agent を動かすには何が必要なのか、現実的なラインで整理します。
必要スキル
- TypeScript + Bun:GBrain のコードベースの 97% が TypeScript。カスタマイズやスキルパック開発をするならこの環境が前提になります。Node.js を触ったことがあれば移行コストは低いけど、Bun 固有の挙動には注意
- PostgreSQL + pgvector:本格運用には PostgreSQL サーバーと pgvector 拡張が必要。PGLite(組み込み WASM 版、起動約 2 秒)で小規模に試せるけど、dream cycle の常駐デーモンはファイルロックの関係で full Postgres が必須
- MCP の基本:Hermes Agent と GBrain を繋ぐのは MCP(Model Context Protocol)。
hermes mcp add gbrain -- gbrain serveが何をしているか理解できれば十分。OAuth 2.1 のスコープ制御まで踏み込むかは用途次第 - embedding の基礎:ベクトル検索の仕組みと、embedding モデルの選び方。GBrain は OpenAI text-embedding-3-large(3,072 次元)がデフォルトで、他にも ZeroEntropy、Voyage AI、Ollama など 16 以上のプロバイダに対応
初期費用の目安
- PostgreSQL:Supabase Free プランなら 0 円で始められます。本格運用は月 $25〜
- embedding API:OpenAI text-embedding-3-large で 1,000 ページあたり $0.10〜$0.30。Ollama でローカル実行すればゼロ
- LLM API:dream cycle の fact extraction に Claude Haiku、think に Claude Opus を使う想定で、個人利用なら月 $5〜$20。バジェット管理(
~/.gbrain/audit/budget-YYYY-Www.jsonl)が組み込みなので上限は必ず設定してください - rerank(オプション):ZeroEntropy zerank-2 がデフォルト。ローカルの llama.cpp cross-encoder なら無料
Supabase と OpenAI のアカウントがあるなら、追加は embedding と LLM の利用分だけ。試すだけならそこまで身構えなくて大丈夫です。
ここだけは見落とさないでほしい — セットアップの重さとコスト
ここまでわりと前のめりで書いてきたので、少しクールダウンします。GBrain、好きだからこそ言いますが、導入ハードルはかなり高いです。
- セットアップが重い:PostgreSQL + pgvector + Bun + GBrain CLI + Hermes Agent + MCP 設定。全部初めてだと半日コースになりかねない。PGLite で簡易スタートはできるけど、autopilot(dream cycle 常駐)は full Postgres 必須
- コストが見えにくい:capture のたびに embedding、search のたびにベクトル + rerank、think のたびに LLM、dream cycle は毎晩 fact extraction。使い込むほど請求額が増えていく構造。バジェット管理は初日にやるべき設定です
- 「とりあえず入れてみた」は最悪の使い方:これが一番言いたいこと。GBrain は何でも覚えてくれる魔法の箱じゃない。何を capture して、どう分類して、どの頻度で dream cycle を回すか —— 記憶の設計がないと、ただゴミが溜まるだけです。weekly brain lint(重複・矛盾・陳腐化・孤立ページの検出)を回したところで、入力設計が雑なら意味がない
- データは増える一方:Tan の本番環境は 14 万 6,000 ページ。個人利用でそこまで行くことは稀でも、
gbrain schema lint --with-dbでの定期的な棚卸しは必要 - DB 運用の基礎は要る:HNSW インデックスの再構築、Supabase 接続プール設定(ポート 6543)、タイムアウト設定。DB に慣れていないとトラブル時に手詰まりになります
- セキュリティは両方見る:GBrain に機密情報を capture する場合、OAuth 2.1 のスコープ制御、サブエージェントの書き込みスコープ制限(
allowedSlugPrefixes)、PII 除外設定が必要。Hermes Agent 側にも prompt injection 防止のセキュリティスキャンがあるけど、外部 brain 層との連携では両方の設定を揃えないと穴ができます
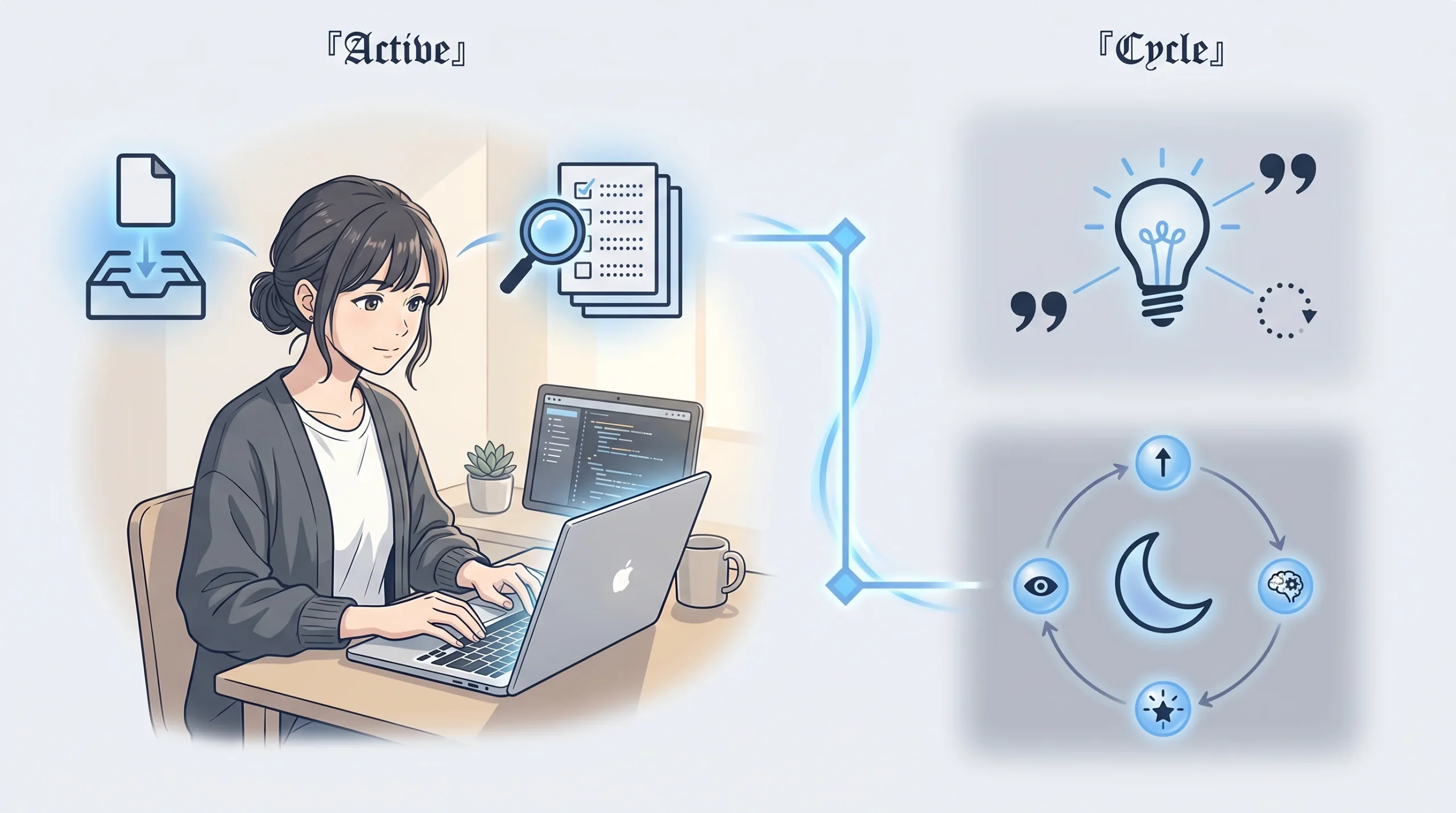
私が GBrain で一番惹かれたのは、dream cycle という発想
GBrain の GitHub を最初に開いたとき、「AI 向けのナレッジベースか、Notion や Obsidian と何が違うんだろう」くらいの温度感でした。正直、期待値は高くなかった。
でも dream cycle のドキュメントを読み始めて、そこから先は一気読みでした。
extract → consolidate → synthesize → publish。AI が毎晩、自分の記憶を見直す。事実を抜き出して、古い情報には「ここまでは有効だった」と期限を付けて、矛盾があれば解消して、compiled truth を書き直して、Git にコミットする。朝には昨日より整理された状態のナレッジが出来上がっている。
これ、自分に置き換えてみてほしいんですが、寝ている間に「昨日までの理解をアップデートしてくれるアシスタント」がいるってことです。しかも原本(timeline)は絶対に書き換えない。理解だけがアップデートされる。この設計を見たとき、「ああ、記憶って保存するものじゃなくて、育てるものなんだ」と腑に落ちた感覚がありました。
もう一つ。GBrain のページが「compiled truth(上半分)」と「timeline(下半分)」に分かれている設計。最新の理解は変わるけど、証拠は変わらない。この分離はナレッジ管理の設計原則として汎用的に使える考え方で、GBrain に限らず覚えておきたい構造です。
とはいえ、誰にでも勧められるかというと、そこは迷います。PostgreSQL に触ったことがない人がいきなり飛びつくのはつらいし、TypeScript + Bun の環境構築で躓くこともある。
でも、あなたが「AI エージェントを長く使いたい」「プロジェクトの文脈を AI に持たせたい」と真剣に考えているなら、GBrain × Hermes Agent は今ある中で最も具体的なリファレンス実装の一つだと思います。私自身、まずは自分の学習ログの管理から試してみるつもりです。
参考にしたもの
一次情報
- GBrain GitHub リポジトリ(Garry Tan / MIT License)
- GBrain 公式サイト
- GBrain Personal Brain チュートリアル
- GBrain: Brain vs Memory ガイド
- GBrain Recommended Schema ドキュメント
- GBrain: What Schemas Unlock
- Hermes Agent GitHub リポジトリ(Nous Research / MIT License)
- Hermes Agent 公式ドキュメント
- Hermes Agent: Persistent Memory
- Hermes Agent: Memory Providers
- Hermes Agent: MCP Integration
関連記事

Gemini 3.5 Flashで個人開発が変わる:4倍速・3.1 Pro超えのGoogle I/O 2026速報

DeepSeek V4 で API課金を見直す ― 個人開発のコスト戦略

Notion Developer Platformで副業ワークフローを自動化する現実解