
Hermes Agent×GBrain×Obsidian:AI記憶の3層併用設計
この記事は約 16 分で読めます
前回の記事で GBrain × Hermes Agent の記憶設計を整理したんですが、書き終わった後にずっと引っかかっていたことがあります。「で、人間はどこで確認するの?」という問題。AI が記憶を整理してくれるのはいい。でも、その記憶を人間が見て「これ合ってる?」「これ要る?」と判断する場所がない。
そこで浮かんだのが Obsidian でした。GBrain、Hermes Agent、Obsidian。この 3 つを「どれが一番いいか」ではなく、「どう分けて使うか」で整理してみます。
なぜこの 3 つを一緒に考える必要があるのか
AI エージェントを 1 〜 2 週間使う分には、記憶の問題はそこまで気にならないです。セッションの中で文脈が通じていれば用は足りる。
でも、1 か月、3 か月と使い続けると、じわじわと問題が出てきます。過去の会話を探しても見つからない。前に決めた方針を AI が忘れている。自分でもどこに何を書いたか分からなくなる。
この状態、何が起きているかというと、作業の実行・AI の記憶・人間の判断が、1 つのツールの中でぐちゃぐちゃに混ざっている。会話ログに設計方針が埋まり、タスクメモと議事録が同じ場所に並び、何が最新で何が古いかも分からない。
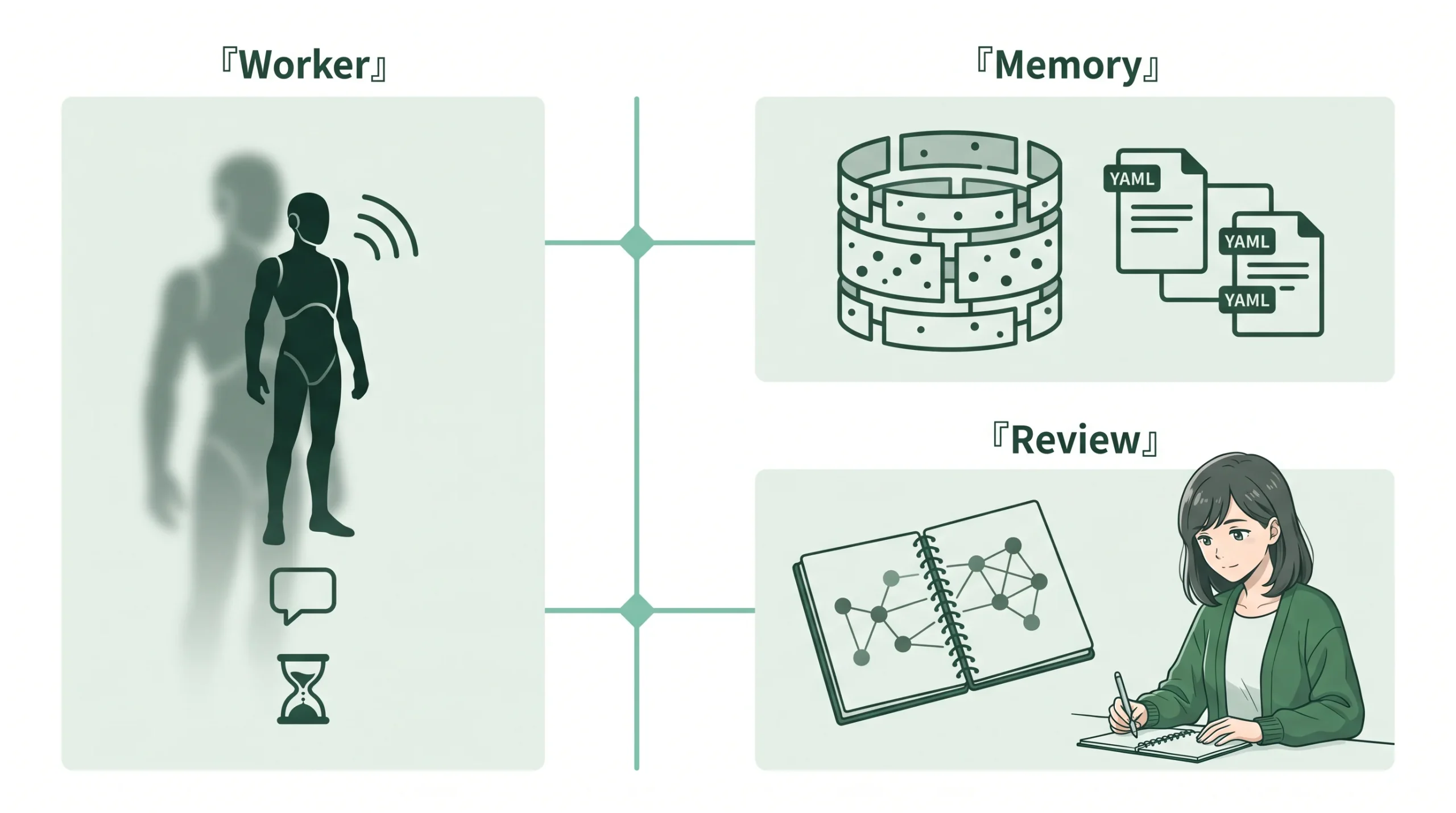
Hermes Agent・GBrain・Obsidian をこの記事で一緒に扱うのは、この 3 つがちょうど「実行」「AI 記憶」「人間の監査」という別の役割を担えるから。比較ではなく、役割分担の話です。
作業者・記憶・監査。3 つの役割を分ける考え方
Hermes Agent は「作業者」
Hermes Agent は調査、コード生成、タスク処理を実行する AI エージェント。300 以上のモデルに対応し、18 以上のプラットフォームで動きます。
内蔵メモリは MEMORY.md + USER.md の約 1,300 トークン(Persistent Memory)。過去セッションの全文検索(Session Search)もある。でもこれは「作業の実行中に最低限の文脈を保つ」ためのもので、長期的に記憶を育てる機能ではない。
Hermes Agent に全部を覚えさせようとすると、1,300 トークンの Core Memory がすぐ溢れるし、古い情報と新しい情報が混ざって、どれが正しいのか分からなくなります。
GBrain は「AI が使う記憶インフラ」
GBrain は capture・search・think・dream cycle の 4 操作で記憶を管理する AI 向けインフラ。pgvector + PostgreSQL でハイブリッド検索し、markdown + YAML frontmatter で保存し、夜間の dream cycle で自動整理する(Brain vs Memory)。
前回の記事で詳しく書いたので繰り返しませんが、要点は「AI が検索しやすく、自動で整理される記憶基盤」という役割。人間が毎日読むノートではなく、AI がバックグラウンドで使うインフラです。
ただ、GBrain は AI にとって最適化された設計なので、人間が「今何が入っていて、何が正しくて、何を消すべきか」を確認しにくい面があります。14 万ページを人間が棚卸しするのは現実的じゃない。
Obsidian は「人間が監査・編集する場所」
Obsidian はローカルの markdown ファイルを管理するノートアプリ。CEO の Steph Ango が掲げる 「File over App」の思想 — アプリより先にファイルがある、ファイルが残ればアプリは替えがきく — がそのまま設計に出ています。
データは全部ローカルの .md ファイル(How Obsidian stores data)。[[internal links]] でページ同士をつなぎ、Graph View で知識の構造を可視化できる。YAML frontmatter でメタデータを付けられるし、コミュニティプラグインで機能拡張もできる。
ここで気づいたんですが、Obsidian と GBrain の共通言語は markdown。同じ .md ファイルを、GBrain は AI の記憶として処理し、Obsidian は人間が読み書きするノートとして開ける。このフォーマットの一致が、併用の前提として地味に大きい。
この記事で一番伝えたいこと
全部を 1 つに詰め込まない。Hermes Agent は作業、GBrain は AI 記憶、Obsidian は人間の監査。この分離が、AI の長期運用で壊れにくい設計になる。
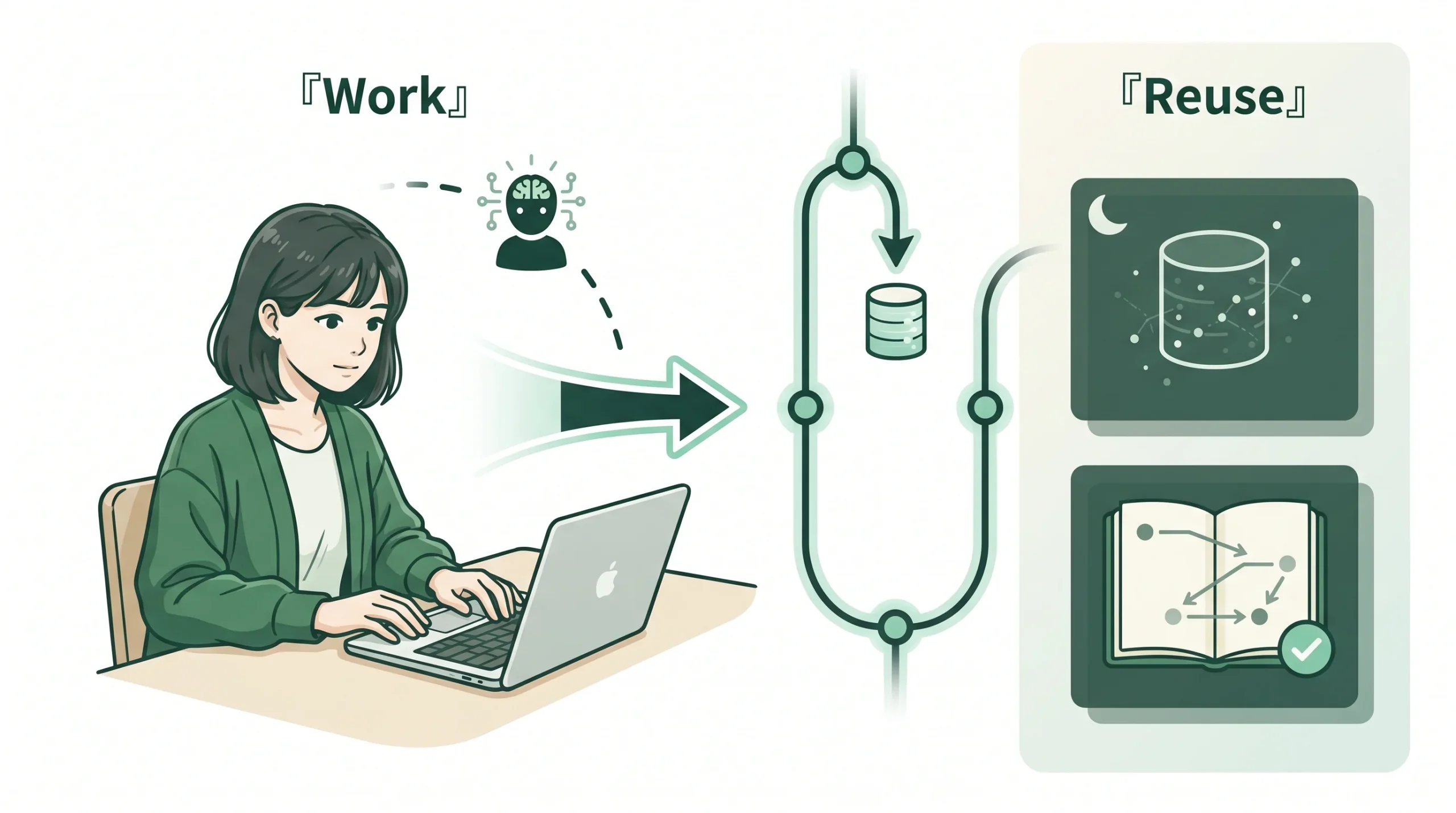
つなぎ方のイメージ: Hermes Agent が作業中に重要情報を GBrain に capture → GBrain が検索・整理・再利用 → 重要な判断や設計方針は人間が Obsidian に抜き出して整理 → 次回以降、Hermes Agent が GBrain と Obsidian 両方を参照して作業する。
この分離で具体的に何がよくなるかというと:
- 作業ログと長期記憶が混ざらない: Hermes Agent のセッション履歴と、GBrain の整理済み記憶が物理的に別。「あの話、会話のどこかにあったはず」を探す必要がなくなる
- AI の記憶を人間が検証できる: GBrain に溜まった情報のうち、本当に重要なものだけを Obsidian に抜き出す。AI が勝手に間違った前提を強化し続けるリスクを、人間のレビューで止められる
- データの寿命が違う: Hermes の会話ログは短命、GBrain の記憶は中長期、Obsidian のノートは半永久。寿命の違うデータを同じ場所で管理すると、古いものと新しいものの区別がつかなくなる
- ツールが変わっても知識が残る: Obsidian のファイルは素の markdown。Hermes Agent が別のエージェントに変わっても、GBrain の仕様が変わっても、Obsidian のノートは 50 年後でも読める
副業として狙うなら、「分け方の設計」自体が商品になる
前回の GBrain 記事でも書きましたが、AI 記憶設計を提案できる人はまだほとんどいません。今回のテーマ「3 層に分けて併用する」はさらにニッチ。
- AI 記憶レイヤー設計コンサルティング: 「Hermes Agent は作業用、GBrain は記憶用、Obsidian は監査用」という設計を、クライアントのワークフローに合わせて構築する。何を GBrain に入れ、何を Obsidian に残すかのルール策定までがサービス
- Obsidian テンプレート × AI 運用ガイド: AI から受け取った情報を Obsidian でどう整理するかのテンプレートセット。フォルダ構造、YAML frontmatter の設計、Graph View の使い方まで含めたガイド
- GBrain → Obsidian 同期の仕組み構築: GBrain の compiled truth を定期的に Obsidian vault にエクスポートして人間がレビューする仕組みの代行。markdown が共通フォーマットだからこそ成り立つ
注意
「3 つのツールを導入すれば全部解決」ではありません。まず自分で 1 か月運用してみて、何をどこに入れるかのルールが自分の中にできてから、初めて他人に提案できます。ルールなしに導入すると、3 つのツールそれぞれにゴミが溜まるだけです。
個人開発なら、Obsidian テンプレートから始めるのが現実的
個人開発者がいきなり Hermes Agent + GBrain + Obsidian の 3 層を全部構築するのは、正直しんどい。PostgreSQL + pgvector + Bun + MCP 設定が必要な GBrain だけでも半日コースです。
私なら、まず Obsidian のテンプレート設計から始めます。
- AI レビューノートのテンプレート: AI が出力した調査結果や判断を、人間がレビューして「採用 / 保留 / 却下」を記録するフォーマット。YAML frontmatter に
status: reviewed、reviewed_date、source: hermes-session-xxxを入れる設計 - プロジェクト記憶の構造設計: フォルダを
decisions/(設計判断)、references/(参考情報)、reviews/(AI 出力レビュー)に分けて、[[internal links]]でつなぐ。Graph View で全体構造が見えるようにする - Obsidian → GBrain 連携のプロトタイプ: Obsidian の vault を GBrain の source として読み込ませる。GBrain は markdown を native に扱えるので、Obsidian で人間が整理したノートが AI の検索対象になる
この「Obsidian テンプレート + AI 連携設計」をパッケージにして公開する個人開発者が出てきたら、需要はあると思います。今のところ、日本語圏にはいない。
収益化を考えるなら、日本語で「併用設計」を語れる人がいない
GBrain 単体の日本語情報もほぼゼロでしたが、「Hermes Agent + GBrain + Obsidian をどう組み合わせるか」を日本語で書いている人は、私が調べた限り皆無です。
- 技術ブログ・チュートリアル: 3 層設計の考え方、具体的なセットアップ手順、Obsidian テンプレートの使い方を日本語で解説する。検索需要はこれから生まれるタイミング
- 有料ガイド: Obsidian vault の設計 → Hermes Agent の MCP 接続 → GBrain の capture / dream cycle 設定まで、段階的に進められるステップバイステップガイド
- 運用テンプレート販売: Obsidian vault テンプレート(フォルダ構造 + YAML frontmatter 設計 + Graph View 設定)を Gumroad 等で販売する
ただし、3 つとも変化が速いプロジェクトです。GBrain は 2026 年 4 月公開、Hermes Agent は頻繁にアップデート、Obsidian もプラグインエコシステムが動き続けている。コンテンツは更新し続ける前提で組んでください。
始めるなら、まず Obsidian だけでいい
3 層全部を一度に導入する必要はないです。むしろ、一気に入れると各ツールの役割が曖昧なまま動き出して、結局どこに何があるか分からなくなる。
段階 1: Obsidian(無料、今すぐ始められる)
- Obsidian を公式サイトからインストール。個人利用は無料
- vault を作って、AI との会話で得た重要な判断・方針・調査結果をノートに整理し始める
- フォルダ構造と YAML frontmatter の設計を自分なりに決める
[[internal links]]と Graph View で知識の構造を可視化する- 必要スキル: markdown の基礎だけ。初期費用: ゼロ
段階 2: Hermes Agent(AI エージェントを導入)
- Hermes Agent をセットアップして、調査・タスク実行を任せる
- 作業結果のうち重要なものを Obsidian に手動で転記してレビュー
- MCP で Obsidian vault を読み込ませれば、過去のノートを参照して作業できる
- 必要スキル: CLI 操作、MCP の基本。追加コスト: LLM API 利用分
段階 3: GBrain(AI 用記憶インフラを追加)
- Hermes Agent の作業量が増えて、手動転記では追いつかなくなったら GBrain を導入
- capture で自動的に記憶を蓄積し、dream cycle で夜間整理
- GBrain の compiled truth を定期的に Obsidian にエクスポートして人間がレビュー
- 必要スキル: TypeScript + Bun、PostgreSQL + pgvector。追加コスト: DB + embedding + LLM API(月 $10〜$30 目安)
全部入れると壊れる。段階的に増やすべき理由
ここからは現実的な話をします。この 3 層設計、考え方としては整理されていますが、運用するとなると相応のコストと手間がかかります。
- 最初から 3 つ入れると破綻する: 何を GBrain に入れて、何を Obsidian に残すかのルールが決まっていない段階で全部導入すると、3 つのツールそれぞれに中途半端な情報が散らばって、分ける前より状況が悪化します。これが一番怖い
- 振り分けルールの設計が必要: 「会話ログは Hermes に残す」「重要な事実は GBrain に capture する」「設計方針と判断は Obsidian に書く」のように、何をどこに置くかのルールを先に決めてから運用する
- GBrain の API コストは使うほど増える: capture のたびに embedding、search のたびにベクトル検索 + rerank、dream cycle は毎晩 LLM。バジェット上限の設定は必須
- AI の記憶は正しいとは限らない: GBrain の compiled truth は AI が自動生成したもの。事実誤認や古い情報が混ざる可能性がある。だからこそ Obsidian で人間がレビューする層が必要で、AI の出力を無条件に信じない姿勢が前提
- 機密情報の扱い: 3 つのツールに情報を分散させるということは、3 つの場所でセキュリティを考える必要がある。GBrain には OAuth 2.1 スコープ制御と PII 除外設定、Obsidian はローカル保存だがデバイス紛失リスク、Hermes Agent にはメモリの prompt injection 防止がそれぞれ必要
私が一番伝えたいのは「全部を AI に覚えさせなくていい」ということ
この記事を書きながら、ずっと考えていたことがあります。
AI エージェントの記憶管理って、つい「全部覚えさせたい」方向に行きがちです。会話も、調査結果も、判断の経緯も、全部 AI の記憶に入れて、いつでも引き出せるようにしたい。その気持ちは分かる。
でも、実際にやってみると分かるんですが、全部を 1 つの場所に入れると「何が本当に大事で、何は忘れていいのか」の判断が誰にもできなくなる。AI に任せると AI の基準で整理されるし、人間が見ようとしても量が多すぎて見切れない。
だから分ける。忘れていいものと残すべきものを分ける行為自体が、記憶の設計です。
Hermes Agent は「今やっている作業」に集中させる。GBrain には「AI が後から検索・再利用する情報」だけを入れる。Obsidian には「人間が判断した、本当に残すべきもの」を置く。この分離ができると、それぞれのツールがかなり素直に動きます。
ただ、3 つ全部を最初から入れるのは勧めません。まず Obsidian で「自分がどんな情報をどう整理したいか」を 1 か月くらい試す。そのルールが固まってから Hermes Agent、さらに必要になったら GBrain。この順番なら、途中で「やっぱり GBrain はまだ要らないな」という判断もできる。
私自身、前回の記事で「学習ログの管理から GBrain を試してみる」と書いたんですが、その前にまず Obsidian で自分の学習ノートの構造を設計し直すところから始めています。AI の記憶インフラを入れる前に、自分が何を覚えておきたいのかを整理する。この順番が、たぶん正しい。
参考にしたもの
一次情報
- Hermes Agent GitHub リポジトリ(Nous Research / MIT License)
- Hermes Agent 公式ドキュメント
- Hermes Agent: Persistent Memory
- Hermes Agent: Memory Providers
- GBrain GitHub リポジトリ(Garry Tan / MIT License)
- GBrain 公式サイト
- GBrain: Brain vs Memory ガイド
- Obsidian 公式サイト
- Obsidian: About(設計思想・5つの柱)
- Obsidian: How Obsidian stores data
- Obsidian: Internal links
- Obsidian: Graph view
- Obsidian: Community plugins
- Steph Ango: File over App(Obsidian CEO エッセイ)
関連記事

Claude Designから即デプロイ――個人開発の初速が変わる

Cursor、Composer 2.5を公開。1/10価格で個人開発のコスト構造が変わる

【Hermes Agent入門 #2】Hermes Agentの始め方:インストールから初期設定まで





